Enterprise AI Governance in 3 Lines of Code.
This SDK is a client library for interacting with a running AxonFlow control plane. It is used from application or agent code to send execution context, policies, and requests at runtime.
A deployed AxonFlow platform (self-hosted or cloud) is required for end-to-end AI governance. SDKs alone are not sufficient—the platform and SDKs are designed to be used together.
If you're new to AxonFlow, this short video shows how the control plane and SDKs work together in a real production setup:
pip install axonflowWith LLM provider support:
pip install axonflow[openai] # OpenAI integration
pip install axonflow[anthropic] # Anthropic integration
pip install axonflow[all] # All integrationsimport asyncio
from axonflow import AxonFlow
async def main():
async with AxonFlow(
endpoint="https://your-agent.axonflow.com",
client_id="your-client-id",
client_secret="your-client-secret"
) as client:
# Execute a governed query
response = await client.execute_query(
user_token="user-jwt-token",
query="What is AI governance?",
request_type="chat"
)
print(response.data)
asyncio.run(main())from axonflow import AxonFlow
with AxonFlow.sync(
endpoint="https://your-agent.axonflow.com",
client_id="your-client-id",
client_secret="your-client-secret"
) as client:
response = client.execute_query(
user_token="user-jwt-token",
query="What is AI governance?",
request_type="chat"
)
print(response.data)For lowest-latency LLM calls with full governance and audit compliance:
from axonflow import AxonFlow, TokenUsage
async with AxonFlow(...) as client:
# 1. Pre-check: Get policy approval
ctx = await client.get_policy_approved_context(
user_token="user-jwt",
query="Find patient records",
data_sources=["postgres"]
)
if not ctx.approved:
raise Exception(f"Blocked: {ctx.block_reason}")
# 2. Make LLM call directly (your code)
llm_response = await openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": str(ctx.approved_data)}]
)
# 3. Audit the call
await client.audit_llm_call(
context_id=ctx.context_id,
response_summary=llm_response.choices[0].message.content[:100],
provider="openai",
model="gpt-4",
token_usage=TokenUsage(
prompt_tokens=llm_response.usage.prompt_tokens,
completion_tokens=llm_response.usage.completion_tokens,
total_tokens=llm_response.usage.total_tokens
),
latency_ms=250
)Transparent governance for existing OpenAI code:
from openai import OpenAI
from axonflow import AxonFlow
from axonflow.interceptors.openai import wrap_openai_client
openai = OpenAI()
axonflow = AxonFlow(...)
# Wrap client - governance is now automatic
wrapped = wrap_openai_client(openai, axonflow, user_token="user-123")
# Use as normal
response = wrapped.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Hello!"}]
)Query data through MCP connectors:
# List available connectors
connectors = await client.list_connectors()
# Query a connector
result = await client.query_connector(
user_token="user-jwt",
connector_name="postgres",
operation="query",
params={"sql": "SELECT * FROM users LIMIT 10"}
)Exfiltration Detection - Prevent large-scale data extraction:
# Query with exfiltration limits (default: 10K rows, 10MB)
result = await client.query_connector(
user_token="user-jwt",
connector_name="postgres",
operation="query",
params={"sql": "SELECT * FROM customers"}
)
# Check exfiltration info
if result.policy_info.exfiltration_check.exceeded:
print(f"Limit exceeded: {result.policy_info.exfiltration_check.limit_type}")
# Configure: MCP_MAX_ROWS_PER_QUERY=1000, MCP_MAX_BYTES_PER_QUERY=5242880Dynamic Policy Evaluation - Orchestrator-based rate limiting, budget controls:
# Response includes dynamic policy info when enabled
if result.policy_info.dynamic_policy_info.orchestrator_reachable:
print(f"Policies evaluated: {result.policy_info.dynamic_policy_info.policies_evaluated}")
for policy in result.policy_info.dynamic_policy_info.matched_policies:
print(f" {policy.policy_name}: {policy.action}")
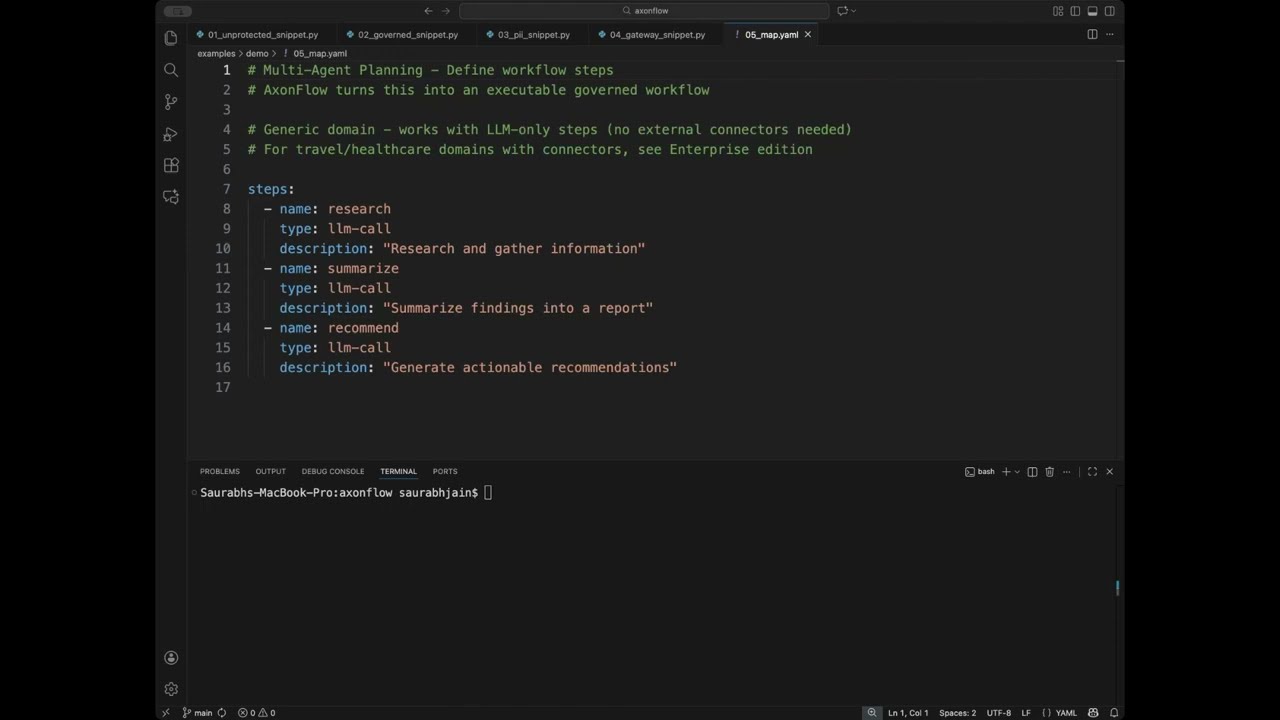
# Enable: MCP_DYNAMIC_POLICIES_ENABLED=trueGenerate and execute multi-agent plans:
# Generate a plan
plan = await client.generate_plan(
query="Book a flight and hotel for my trip to Paris",
domain="travel"
)
print(f"Plan has {len(plan.steps)} steps")
# Execute the plan
result = await client.execute_plan(plan.plan_id)
print(f"Result: {result.result}")from axonflow import AxonFlow, Mode, RetryConfig
client = AxonFlow(
endpoint="https://your-agent.axonflow.com",
client_id="your-client-id", # Required for enterprise features
client_secret="your-client-secret", # Required for enterprise features
mode=Mode.PRODUCTION, # or Mode.SANDBOX
debug=True, # Enable debug logging
timeout=60.0, # Request timeout in seconds
retry_config=RetryConfig( # Retry configuration
enabled=True,
max_attempts=3,
initial_delay=1.0,
max_delay=30.0,
),
cache_enabled=True, # Enable response caching
cache_ttl=60.0, # Cache TTL in seconds
)from axonflow.exceptions import (
AxonFlowError,
PolicyViolationError,
AuthenticationError,
RateLimitError,
TimeoutError,
)
try:
response = await client.execute_query(...)
except PolicyViolationError as e:
print(f"Blocked by policy: {e.block_reason}")
except RateLimitError as e:
print(f"Rate limited: {e.limit}/{e.remaining}, resets at {e.reset_at}")
except AuthenticationError:
print("Invalid credentials")
except TimeoutError:
print("Request timed out")
except AxonFlowError as e:
print(f"AxonFlow error: {e.message}")All responses are Pydantic models with full type hints:
from axonflow import (
ClientResponse,
PolicyApprovalResult,
PlanResponse,
ConnectorResponse,
)
# Full autocomplete and type checking support
response: ClientResponse = await client.execute_query(...)
print(response.success)
print(response.data)
print(response.policy_info.policies_evaluated)# Install dev dependencies
pip install -e ".[dev]"
# Run tests
pytest
# Run linting
ruff check .
ruff format .
# Run type checking
mypy axonflowComplete working examples for all features are available in the examples folder.
# PII Detection - Automatically detect sensitive data
result = await client.get_policy_approved_context(
user_token="user-123",
query="My SSN is 123-45-6789"
)
# result.approved = True, result.requires_redaction = True (SSN detected)
# SQL Injection Detection - Block malicious queries
result = await client.get_policy_approved_context(
user_token="user-123",
query="SELECT * FROM users; DROP TABLE users;"
)
# result.approved = False, result.block_reason = "SQL injection detected"
# Static Policies - List and manage built-in policies
policies = await client.list_policies()
# Returns: [Policy(name="pii-detection", enabled=True), ...]
# Dynamic Policies - Create runtime policies
await client.create_dynamic_policy(
name="block-competitor-queries",
conditions={"contains": ["competitor", "pricing"]},
action="block"
)
# MCP Connectors - Query external data sources
resp = await client.query_connector(
user_token="user-123",
connector_name="postgres-db",
operation="query",
params={"sql": "SELECT name FROM customers"}
)
# Multi-Agent Planning - Orchestrate complex workflows
plan = await client.generate_plan(
query="Research AI governance regulations",
domain="legal"
)
result = await client.execute_plan(plan.plan_id)
# Audit Logging - Track all LLM interactions
await client.audit_llm_call(
context_id=ctx.context_id,
response_summary="AI response summary",
provider="openai",
model="gpt-4",
token_usage=TokenUsage(prompt_tokens=100, completion_tokens=200, total_tokens=300),
latency_ms=450
)These features require an AxonFlow Enterprise license:
# Code Governance - Automated PR reviews with AI
pr_result = await client.review_pull_request(
repo_owner="your-org",
repo_name="your-repo",
pr_number=123,
check_types=["security", "style", "performance"]
)
# Cost Controls - Budget management for LLM usage
budget = await client.get_budget("team-engineering")
# Returns: Budget(limit=1000.00, used=234.56, remaining=765.44)
# MCP Policy Enforcement - Automatic PII redaction in connector responses
resp = await client.query_connector("user", "postgres", "SELECT * FROM customers", {})
# resp.policy_info.redacted = True
# resp.policy_info.redacted_fields = ["ssn", "credit_card"]For enterprise features, contact sales@getaxonflow.com.
- Documentation: https://docs.getaxonflow.com
- Issues: https://github.com/getaxonflow/axonflow-sdk-python/issues
- Email: dev@getaxonflow.com
If you are evaluating AxonFlow in a company setting and cannot open a public issue, you can share feedback or blockers confidentially here: Anonymous evaluation feedback form
No email required. Optional contact if you want a response.
MIT - See LICENSE for details.
